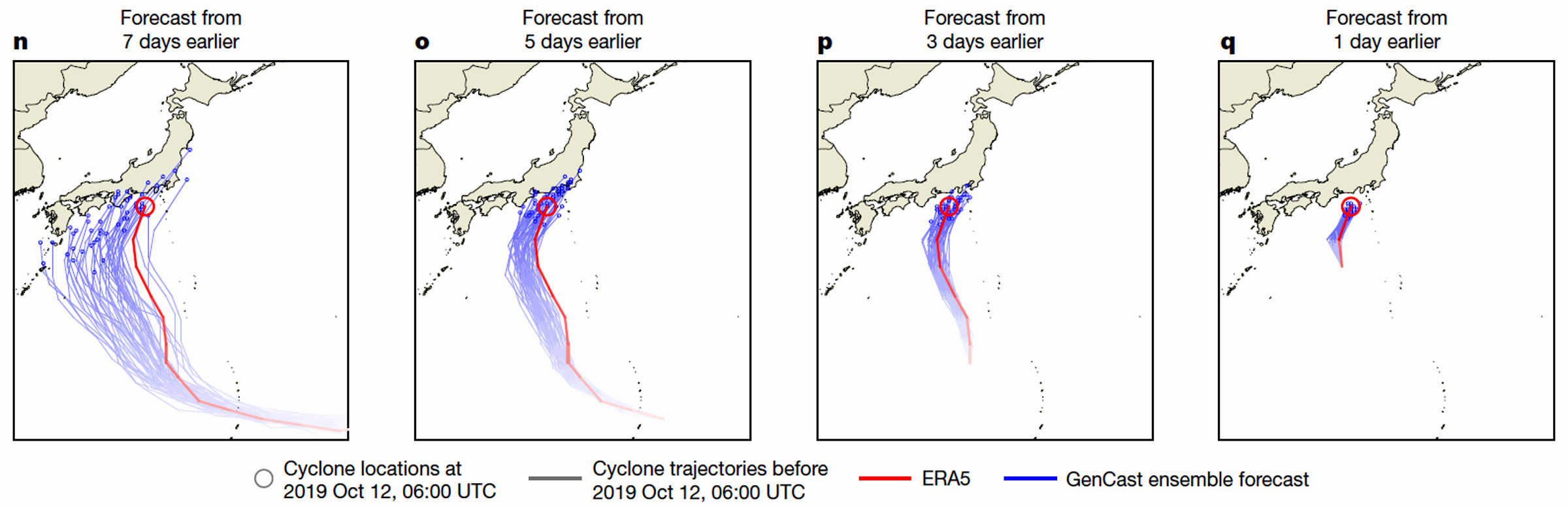
Superorkaan Hagibis vlak voor deze op 12 oktober 2019, 06 UTC, de Japanse kust treft. Deze orkaan is als voorbeeld in het toeleverend artikel van Price uitgewerkt.
Op meerdere plaatsen op aarde probeert men machineleren (ook AI genoemd) in te zetten voor een betere weersvoorspelling. Dit met toenemend succes.
Basaal redenerend kun je het weer op twee manieren voorspellen: òf door heel hard aan de natuurwetten te rekenen, of door weersituaties uit het verleden aan een machineleer-computer te voeden.
De beste natuurkundemachine ter wereld staat bij het European Centre for Medium-Range Weather Forecasts , dat het wiskundige ENS-model gebruikt voor weersvoorspellingen op de middellange termijn. Dat vraagt om enorme rekenkracht op een supercomputer en de uitkomst duurt uren.
Het model GenCast is door DeepMind (van Google) gevoed met weergegevens van over de hele wereld van 1979 tot 2018 en heeft die op de AI-manier gebruikt om het mondiale weer van 2019 te voorspellen. GenCast doet er acht minuten over om het weer 15 dagen vooruit te voorspellen. Ilan Price is lead author van het project.
De AI-uitkomst is vergeleken met het echte weer in 2019, en met wat ENS ervan maakte. GenCast scoorde op een van tevoren afgesproken lijstje op 97% van de items beter.
DeepMind heeft de code van de software, alsmede de gekozen parameters, publiek toegankelijk gemaakt. Dit wordt door andere geleerden zeer op prijs gesteld. Inmiddels is ook het Europese centrum met een machineleer-programma bezig.
Achteraan het Nature News-artikel wordt doorverwezen naar
Het oorspronkelijke DeepMind-artikel waarop de publicatie in Nature News gebaseerd is
Een vergelijkbaar artikel van geleerden van Huawei uit Shenzhen (China)
Een eerdere Google-publicatie van het NeuralGCM-programma, dat natuurkunde en AI combineert voor korte- en lange termijn weersvoorspellingen
Deze artikelen zijn allen Open Access, maar lezing ervan moet het algemene publiek worden afgeraden. Ze zijn uiterst technisch.
In het toeleverend artikel van Price wordt de baanvoorspelling van de superorkaan Hagibis als voorbeeld genoemd. ERA5 is de ‘europese’ voorspelling (rode lijn). De blauwe set lijnen is wat GenCast ervan maakt, steeds korter van tevoren. De cirkel is waar het model stopt en dat is vier uur voor de orkaan aan landkomt.
Dit is een verhaal dat een aantal kanten op uitwaaiert omdat het over een gelaagde werkelijkheid gaat. Het verhaal is gebaseerd op de MIT Technology Review van 04 december 2020 .
Natural Language Processing (NLP) Techondernemingen willen graag dat hun software zo goed mogelijk natuurlijke taal begrijpt en uitingen kan doen die daar zo dicht mogelijk in de buurt komen. Dat doen ze met Artificial Intelligence (AI) die draait op computers met een neurale netwerk-structuur.
Als je een neurale netwerk-computer wilt leren om kattenplaatjes te herkennen, voer je heel veel foto’s van katten toe en iedere kaar vertel je tegen de computer achteraf of dit wel of geen kat was. Dat heet trainen. In de krochten van het namaakbrein gebeurt iets in de sfeer van groeiende en krimpende verbindingen (wat precies, weet niemand) en na voldoende training weet de computer voortaan met grote precisie bij een nieuw plaatje of het wel of geen kat is. Dat werkt mogelijk ook voor uitstrijkjes en het vouwen van eiwitten en andere goede doelen, en soms zijn die programma’s heel goed.
Natuurlijke taal is heel wat ingewikkelder als een kattenplaatje of een uitstrijkje. Het vraagt hele zware computers, heel veel tijd en heel veel tekst en heel veel deskundigheid. Waaronder ethische deskundigheid, want namaaktaal is riskante business.
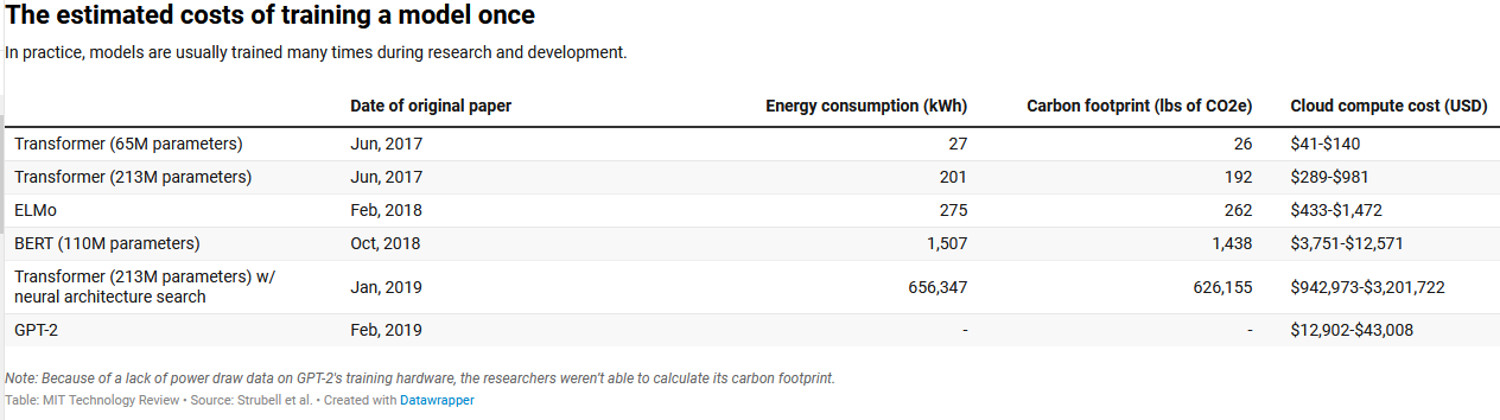
Grote NLP-modellen vreten stroom In een artikel dd 5 juni 2019 hebben de Amherst-onderzoekers Emma Strubell, Ananya Ganesh en Andrew McCallum uitgerekend wat een trainingssessie energetisch betekende ( zie Energy and Policy Considerations for Deep Learning in NLP, https://arxiv.org/abs/1906.02243 ).Dat bleek interessant. Onderzocht werden Transformer, ELMo, BERT en GPT-2. ELMo is een soort basisprogramma dat de betekenis van woorden in hun context kan coderen (https://allennlp.org/elmo ) . Het is Open Source. Transformer is door Google ontwikkeld en BERT is daar de zoon van. BERT is het programma dat Google gebruikt om menselijke vragen op zijn zoekmachine te snappen (https://blog.google/products/search/search-language-understanding-bert/ ). Het is hun cash cow. GPT-2 is Open AI . Neural Architecture Search (NAS) is een techniek om het ontwerp van neurale netwerk-computers te automatiseren (https://en.wikipedia.org/wiki/Neural_architecture_search ).
Dat veel namen uit Sesam straat lijken te komen, was in het begin toeval en daarna traditie als de ene wetenschapper voortbouwde op de andere.
Men liet de programma’s een dag draaien op één GPU (een Graphics Processing Unit, een goed uitlegartikel op https://towardsdatascience.com/what-is-a-gpu-and-do-you-need-one-in-deep-learning-718b9597aa0d ) om het gevraagde vermogen te meten, en berekenden daarna, op basis van het aantal uren dat het model voor een taak specificeerde, wat één volledige trainingssessie aan stroom kostte.
Een trainingssessie t.b.v. Google’s BERT kostte 1507kWh . Dat is nog te overzien: het is het jaarlijkse elektriciteitsverbruik van ongeveer een half Nederlands huishouden of zowat een vliegretourtje New York – San Francisco. Wordt het ingewikkelder (meer parameters en en de NAS-procedure erbij) dan ontploft het energieverbruik dramatisch naar bijvoorbeeld ruim 656000 kWh: het jaarlijkse stroomverbruik van 220 Nederlandse huizen (en dat voor één trainingssessie). Bij de in de VS gebruikelijke stroommix is dat 626155 lb CO2 (dat is 284 ton).
Het wordt sappig in kaart gebracht met bovenstaand diagram: een gemiddelde Amerikaanse auto produceert over zijn levensduur (Brandstof en fabricage samen) ongeveer 126000 lbs CO2 . Een opgepompte trainingssessie is goed voor vijf Amerikaanse auto’s, genomen over hun gehele levensduur. Enz. Bovenstaand is een ondergrens omdat modellen vaker dan één keer getraind worden, en uiteraard omdat er straks een heleboel bezitters van zo’n model zijn.
Timnit Gebru Hier komt Timnit Gebru in beeld.
De ouders van Timnit Gebru komen uit Eritrea, zijn naar Ethiopië gevlucht waarna Timnit Gebru geboren en opgegroeid is in Addis Abeba. Uiteindelijk is het gezin in de VS aangekomen, waar Timnit Gebru afgestudeerd is aan Stanford in de elektrotechniek. ( https://en.wikipedia.org/wiki/Timnit_Gebru ). Ze heeft zich als wetenschapper ontwikkeld tot een mondiaal toonaangevende authoriteit op het gebied van Data mining en de ‘Bias’ (zoiets als ingebakken vooroordelen en verborgen selectiekeuzes) daarvan . Het is de basis voor “AI Ethics”. Van haar is bijvoorbeeld de observatie dat als je met Google Street View in een woonwijk meer pickup trucks zag dan sedans, die wijk met grote waarschijnlijkheid Republikeins stemde. En ook de observatie dat het gezichtsherkenningssysteem van Amazon meer moeite had met gezichten van donkere vrouwen dan elk ander gezichtsherkenningssysteem. Ze meent dat op dit moment gezichtsherkenning een te gevaarlijke techniek is om voor juridische en veiligheidsdoelen te gebruiken.
Maatschappelijk heeft ze haar afkomst niet verloochend. Ze is altijd voor diversiteit blijven strijden en bijvoorbeeld het Black in AI – platform opgericht.
Het dienstverband bij Google ging lang goed. Ze werd er zoiets als hoofd Ethische Zaken. Bij Google werkt een van de meest diverse AI-teams ter wereld. Timnit Gebru heeft meegewerkt aan tientallen papers en ze werd er de beroemdheid zie ze nu is.
Timnit Gebru By TechCrunch – https://www.flickr.com/photos/techcrunch/30671211838/, CC BY 2.0, https://commons.wikimedia.org/w/index.php?curid=97266712
Maar toen ging het fout. De details van het arbeidsconflict zijn (althans dd 4 dec 2020) niet bekend omdat beide partijen er (tot dan) over zwegen. Desalniettemin resoneerde het ontslag (al dan niet vrijwillig) over de hele wereld. Ruim 1400 mensen binnen Google en ruim 1900 erbuiten tekenden een protestbrief.
De nadelen van grootschalige Natural Language Processing Wel duidelijk is dat het om een nog niet officieel gepubliceerd paper ging met de fraaie naam “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” en het benoemde vier wezenlijke nadelen van de grote NLP-programma’s waar Google aan werkt. Dat bleek uit de eerder genoemde MIT Technology Review van 4 december. De redactie heeft het paper niet gepubliceerd, omdat het een nog eerste versie was, en omdat vier medeauteurs, die nog bij Google werken, hun naam liever niet bekend zagen. Een vijfde auteur, Emily Bender, heeft een vaste aanstelling aan de Universiteit van Washington en had niet wat te vrezen bij het geven van inzage in de tekst (een voordeel van academische vrijheid). Zodoende kon er een samenvatting naar buiten gebracht worden.
Grote modellen kosten vreselijk veel energie en geld. Dat is oneerlijk. Grote rijke instellingen kunnen NLP betalen, maar de klimaateffecten worden vooral gedragen door arme gemeenschappen.
Grote modellen vreten voor hun training onbeheersbaar veel data, zijnde teksten. Researchers voeren de datahonger vanuit het Internet en het is daarom niet uit te sluiten dat er ook een hoop rascistische en sexistische taal naar binnen gulpt. Landen en gemeenschappen die minder toegang hebben tot Internet blijven ondervertegenwoordigd, evenals bewegingen als Black Lives Matter en MeToo, die op subtiele wijze een eigen woordgebruik hebben op gebouwd. Een mooi stukje sociolinguïstiek in de praktijk.
De meeste AI-onderzoekers erkennen dat grote NLP-modellen taal niet echt begrijpen, maar vooral manipuleren (en dat doen ze heel goed). Dat gaat geld opbrengen en daarom investeert de Big Tech erin. Het kritische paper kwam even niet zo goed uit. Men zou ook kunnen investeren in AI die taal begrijpt, minder energie verbruikt en met kleinere datasets werkt die beter voor te bewerken zijn voor ze naar binnen geslurpt worden. Het niet-gepubliceerde paper bevat volgens Bender aanzetten in die richting.
De geproduceerde taal is goed genoeg om betrouwbaar te lijken, maar niet om het werkelijk te zijn. Een vertaalnetwerk van Facebook vertaalde in 2017 het Arabische ‘Goede morgen’ van een Palestijn in ‘Val ze aan’ in het Hebreeuws en dat resulteerde in zijn arrestatie.
Het menselijke zenuwstelsel Anderhalf pond levend weefsel levert spelenderwijs goed taalgebruik en verbruikt ca 200kWh per jaar.
(Dit is een fantasie-eiwit in de vorm van de menselijke hersenen)
In dit artikel een excursie in een gebied waarover ik normaliter niet schrijf, namelijk biochemie in relatie met medische zaken. Ik weet daar te weinig van.
Elk eiwit is een heel lang kralensnoer. De kralen zijn aminozuren en daar zijn er twintig verschillende van, die alle leven op aarde dragen. Elke combinatie in elke volgorde is denkbaar en een kralensnoer kan van enkele tot enkele duizenden kralen lang zijn. Zodoende zijn er miljarden verschillende eiwitten – in het menselijk lichaam alleen zo’n 20.000. Van het bindweefseleiwit collageen tot insuline tot keratine in je huid en haren tot insuline. En tot het spike-eiwit van het Coronavirus.
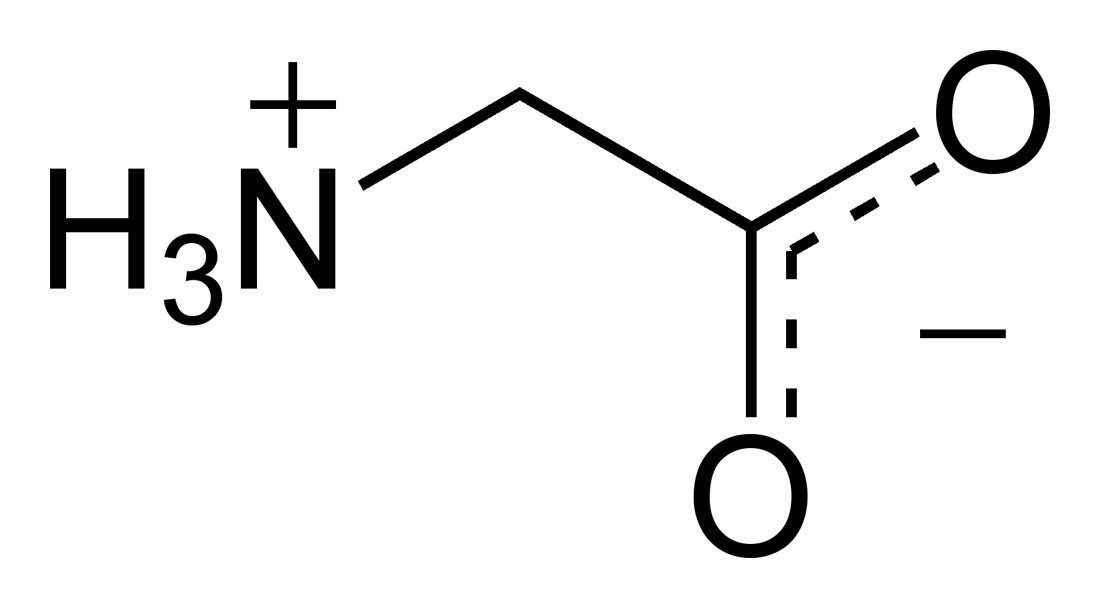
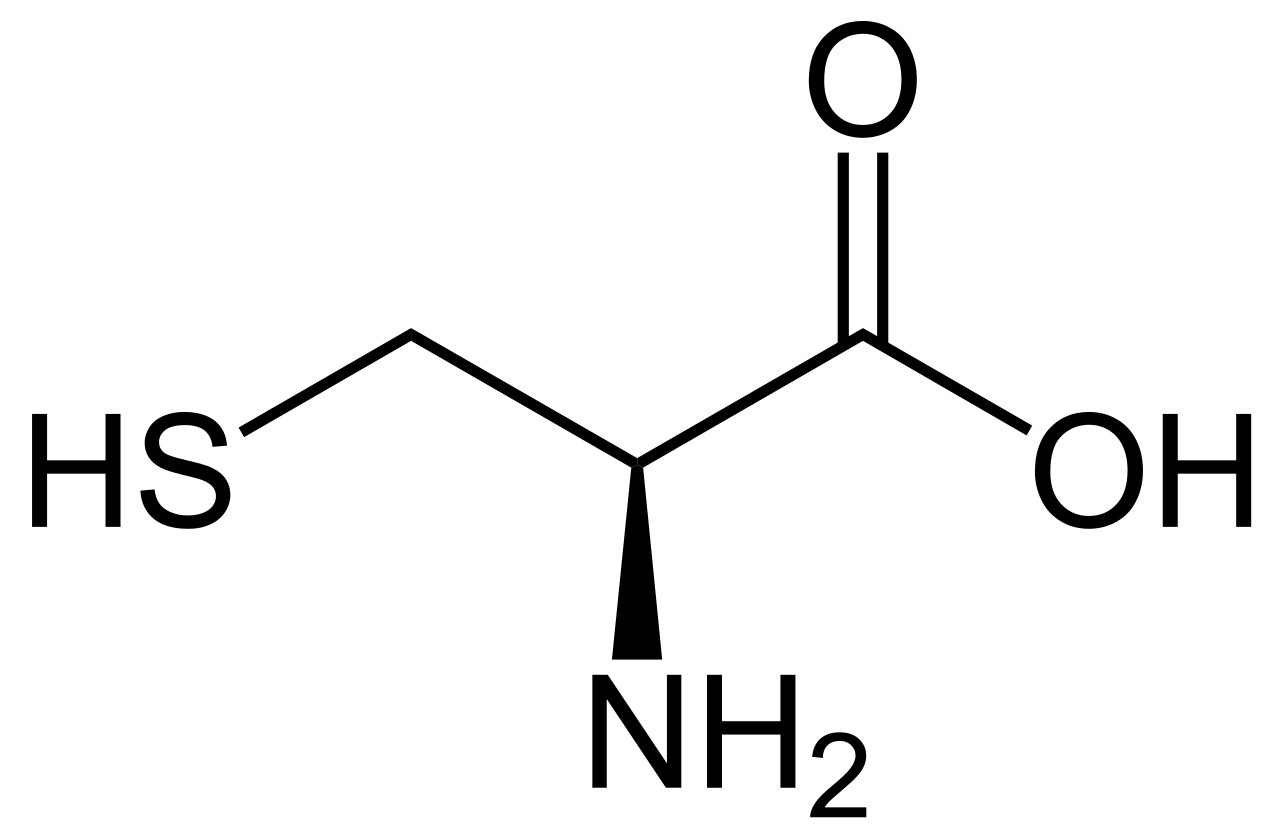
Het eenvoudigste aminozuur is glycine (links en midden). Alle 19 andere aminozuren zijn variaties op dit thema door toevoeging van extra atoomgroepen. Rechts bijvoorbeeld cysteïne dat een extra zwavelgroep heeft en o.a. in je haren zit. Aminozuren koppelen (‘rijgen’) op vaste wijze doordat de rechterkant van het ene molecuul (rood) bindt met de linkerkant van het andere molecuul (blauw). De zwarte assen zijn draaibaar om hun hartlijn. Sommige nevengroepen, zoals de zwavelgroep, kunnen ook ‘zijwaarts’ koppelen. (Om in de kralensnoer-beeldspraak te blijven: het is of sommige kralen magnetisch zijn). Daardoor gaat het snoer spontaan kronkelen tot de laagste energietoestand bereikt is.
Als een gewoon kralensnoer in elkaar gefrommeld is, is dat vervelend. Maar het leven op aarde vereist dat het aminozuur-kralensnoer in elkaar gefrommeld is. Als het spike-eiwit van Corona gewoon een rechte lijn van aminozuren zou zijn, deed het niks. Maar opgefrommeld tot de voor dat eiwit gunstigste vorm heeft het een ruimtelijke structuur die past op een receptor op een longcel, die toevallig een complementaire ruimtelijke structuur heeft. Cysteinehoudende aminozuren pakken elkaar vast met hun zwavelatomen en vormen zo de vezels waaruit je haren bestaan.
Insuline
De aminozuurvolgorde bepalen van een eiwit kan men tegenwoordig min of meer routinematig. Er verschijnen er mondiaal honderden per jaar. Vervolgens moet van die volgordes de ruimtelijke structuur bepaald worden, en dat is hogeschoolwerk.
Het kan experimenteel met bepaalde laboratoriumtechnieken, maar dat kan tonnen en jaren per eiwit kosten. Het kan ook op de computer, en wel volgens twee strategieën: een klassieke algoritmische en een AI-methode met neurale netwerken. De klassieke algorithmische is van Mohammed Al Quraishi van Columbia University (de wetenschap is veelkleurig). Die werkt snel (supercomputer, orde van grootte van seconden), maar minder precies. Soms is dat goed genoeg of is dat vanwege de snelheid beter. De AI-methode is waar nu de spectaculaire vernieuwing zit. Die werkt trager (enkele dagen computertijd), maar is onwaarschijnlijk precies. De onzekerheid in de positie is bij tweederde van de doorgerekende en gecontroleerde eiwitten orde van grootte van 0,16nanometer, orde van grootte van de diameter van een atoom. Preciezer dan dat haalt ook het lab niet, ook al omdat door de warmtebeweging de atomen nooit helemaal stil liggen.
Het AI-programma heet AlphaFold en maakt deel uit van een familie, waarvan een ander lid de wereldkampioen GO versloeg. De familie is ontwikkeld door de van oorsprong Britse onderneming DeepMind ( https://en.wikipedia.org/wiki/DeepMind ), die nu eigendom is van Google’s moederholdiong Alphabet. Dat roept veel politieke en ethische vragen op. Een nadere beschrijving van AlphaFold is te vinden op https://en.wikipedia.org/wiki/AlphaFold .
AI-programma’s worden getraind met heel veel, reeds bekende, voorbeelden. AlphaFold heeft er 170.000 toegevoerd gekregen (eiwitten waarvan de volgorde en de structuur dus al eerder bepaald waren). Dat duurde een paar weken. Vervolgens gebeurt er iets geheimzinnigs in de neurale netwerken wat vooralsnog niemand kan navertellen (AI heeft een replicatieprobleem) , en dan rolt er een oplossing uit die vaak net zo goed is als de beste laboratoriumbepalingen. Researchers zouden erg graag willen weten hoe dat geheimzinnige proces precies verloopt ‘Dan gaan er duizend bloemen bloeien’ aldus Baker, een bekend onderzoeker op dit gebied.
Van de ongeveer 20.000 menselijke eiwitten is van ongeveer 5000 de ruimtelijke structuur bekend. Die andere 15.000 zijn in principe allemaal potentiële doelwitten voor medicijnen.
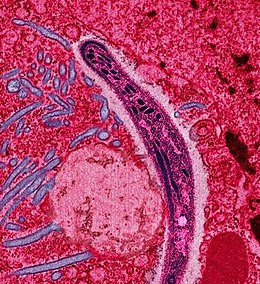
DeepMind wil zich gaan toeleggen op de parasitaire ziektes leishmaniasis, malaria en slaapziekte. Daar slingeren nog een heleboel onontdekte eiwitstructuren rond.
Malariaparasiet SVG-version of Image:Esculaap3.png by Evanherk, GFDL, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=3730168